
|
On 23rd July 2020, I did a short presentation and online Q&A session for StatWars, an initiative aimed at promoting careers in data, science and engineering to primary and secondary school pupils. Talking about data visualisation to schoolchildren was a daunting task but I took the opportunity to discuss the fundamentals that I think are both interesting and valuable to all ages. The session was recorded and is now available on Youtube. If you have any thoughts or questions about anything I discuss in this video then please get in touch as I'd love to hear from you.
0 Comments
It’s been a busy few months. On top of my full time job as a Business Intelligence Officer (and a parent), I’ve delivered some great data visualisation workshops and had the joy of visiting the beautiful city of Ann Arbor to speak at a conference at the University of Michigan. I’ve also become a student again. I’m currently studying online for an MSc in Psychology with Coventry University. This has come as a surprise to some people as the importance of Psychology to data visualisation is not always well understood. However, for me Psychology is the most important aspect of data visualisation and I’d like to tell you why. Why Psychology?My initial introduction into the world of data visualisation came through attending a workshop by Stephen Few in 2013. I’d still recommend his book ‘Show Me The Numbers’ as one of the best introductions to the topic, alongside Alberto Cairo’s ‘The Functional Art’. One of the things I appreciate most in the writings of Stephen Few and Alberto Cairo are their appreciation of how understanding human behaviour is key to creating effective data visualisations. The most fundamental reason why understanding Psychology is key to creating good data visualisations comes through considering our goal of converting data into wisdom: 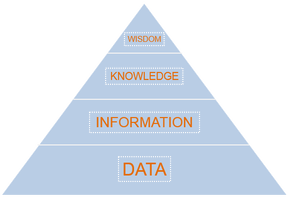 The success of a data visualisation should always be judged on whether it has had its intended impact on its audience. This usually equates to the successful transformation of data into wisdom. An understanding of Data Science and Statistics can help us turn our data into information. However, it is turning information into knowledge that I believe is the most challenging and important aspect of the journey from data to wisdom. Information is presented as pixels/ink on a screen/page while knowledge and wisdom are found in the overwhelmingly complex interplay between the 90bn+ neurons in the human brain. Through studying Psychology I aim to develop my understanding of how to bridge this gap from information to knowledge so that I can develop my understanding of what makes an effective data visualisation. The 2 aspects of Psychology that most directly relate to data visualisation are perception and cognition: Perception (noun) “the ability to see, hear, or become aware of something through the senses.”  Cognition (noun) “the mental action or process of acquiring knowledge and understanding through thought, experience, and the senses.”  Human beings are a highly visual species. Sight is the sense that most strongly influences, not only how we see the world, but also how we think about and try to understand it. This is the simple reason why creating visualisations is the most effective way to communicate with data. Through studying Psychology, I aim to learn more about perception as the first stage of interpreting any data visualisation. The next stage involves extracting information from that visualisation in order to turn it into knowledge. A fully functioning optic system will have no problem presenting our minds with the visual image of a chart or a table, but what cognitive processes take place to allow us to interpret and understand what we are perceiving? Studying cognition is therefore fundamental to understanding how we can best turn information into knowledge. One of my main objectives in studying Psychology is to better understand the complex processes and interactions that occur within our perceptual and cognitive systems when we are presented with a data visualisation. People are Always More Important than Technology...In an increasingly data-driven world, it is important to remember that people are always the most important aspect of any process. People’s habits and ideas are also the most difficult thing to change. Through studying Psychology, my ambition is to further my understanding of people. I want to know more about how we see, think and communicate so that I can apply this knowledge to the challenge of how to effectively communicate within our data-driven world.
Better technology will not provide the solution to this challenge. Only Psychology can provide the answers to the big questions in data visualisation. ______________ If you’d like to know more then please consider attending or hosting one of my workshops (see events) and please don’t hesitate to get in touch if you have any questions or comments.
I can’t remember where I first heard this quote but it’s one of the most useful tips I’ve ever received. I regularly find myself passing this pearl of wisdom on to anyone who will listen and if you’re reading this then I want you to remember it as well. The operating system of the human mind is highly visual. If I were to ask you to think of a pink elephant, you will likely create a kind of faint impression of a pink elephant within your mind and this impression will be very much visual rather than verbal or auditory.  However, while our minds and thoughts tend to operate visually, too often we rely solely on verbal language when communicating our ideas and this often leads to unnecessary misunderstandings. Sketch your ideas Before any report or data visualisation is developed, you first need to understand the requirement. How clearly that requirement can be defined plays a huge role in how effective the final product will be. Even at this early stage in our design process you can improve communication by creating images to share ideas. Now you may be thinking that creating a visual representation of your ideas is too time consuming. However, it really doesn’t have to be and my advice here is to “sketch, sketch, sketch”. This approach was initially inspired by a presentation I saw a few years ago by Nigel Hawtin (see http://nigelhawtin.com/). Sketching is quick and easy and you won’t become attached to your first drafts in the same way that you would if you’ve spent ages pulling a visualisation together using an IT tool. Using a pencil and paper it can take a matter of minutes to turn your ideas into images that will help both you and your audience to better understand and agree your requirements. Building on this shared understanding, your drawings can become the foundation of your design as they go through multiple iterations. Eventually you'll find them coming to life with real data as you build the final visualisation in your chosen IT tool. I'll be honest, I can’t draw. My artistic expression is limited to scribbles and stickmen, but that’s fine. As the old Chinese proverb says “a picture is worth a thousand words”. Over the years, I’ve found my child-like sketches to be an invaluable part of my process for agreeing reporting requirements and designs.  So remember the wisdom of Steve Jobs - if you want to get your message across quickly and clearly then don’t just ask people what they want, show them what they can have.  There are several common themes running across these 3 fantastic books. I think they represent an important pivot in (a) the way we human beings understand ourselves and (b) how communities, organisations and nations can be better governed/ organised. I would summarise this grandiose claim into 3 central ideas:
I also love how these books all lead with the data and use simple, highly effective visualisations to powerfully illustrate their ideas.  I highly recommend these books to anyone. If you have any thoughts you’d like to share or if you have any related recommendations for me then please get in touch.
I thought it might be helpful to provide a quick concrete example of good data visualisation practice. Following my last post, my mind naturally returned to the topic of pigeons and, amazingly, a quick Google search threw up a useful example. The following donut chart comes from www.londonpidgeons.co.uk and I think it provides a useful case study of some of the simple changes that can be made to allow a data visualisation to more effectively communicate its message 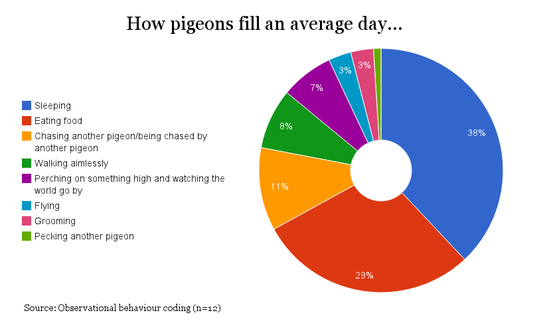 Issues with this visualisation include:
I’ll admit that I may be taking this pigeon analysis a bit too seriously, however, it is still the case that a simple bar chart would have communicated this information much more effectively. To make my point I created the following in Google Sheets in about 2 minutes: 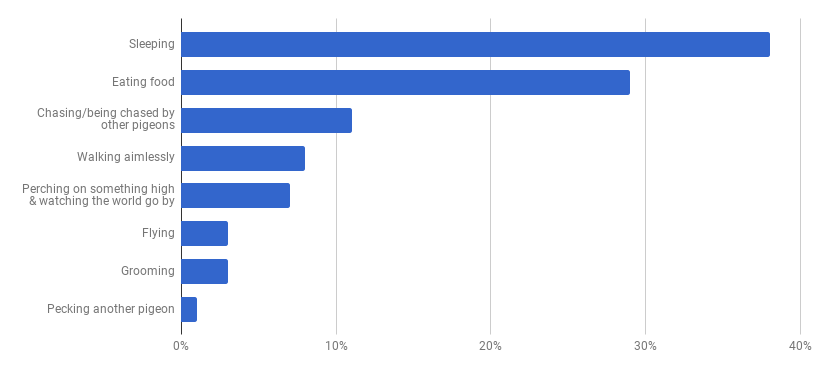 At first glance you may think that this doesn’t have the same visual appeal as the donut, however, our objective is communication and you can certainly read the data much more clearly in this bar chart than you could from the donut chart above. The 2 simple reasons for this are:
Nothing is a given in data visualisation though and so if you disagree then please get in touch. The benefits of effective data visualisation can be substantial. My concern is that good practice is often just equated with use of the latest tools. Flashy visual gimmicks are usually a distraction from our ultimate aim. Q: What should our ultimate aim be when creating a data visualisation? A: An efficient presentation which effectively communicates its intended message. So the purpose of data visualisation is communication. With this in mind, let’s consider the purpose of communication and cut that back to basics. Q: How do we effectively communicate our intended message? A: By clearly stating and presenting the message in a way that your audience can understand. This isn’t rocket science, but when we consider what constitutes effective communication, it is certainly not the tools we use that come to mind. Whether we are communicating verbally, by phone, by e-mail or using a carrier pigeon, it is the form and content of the message that determines whether it will be clearly understood by its intended audience. While we need to understand how to use our tools, it is not the tools that determine the quality of our message.  Carrier pigeon (not actual size) Back to data visualisation and the same applies. In order to communicate effectively with data, we need to know our tools but, most importantly, we need to know how to communicate our message.
Writers like Edward Tufte, Stephen Few and Alberto Cairo have provided great insight into the cognitive aspect of data visualisation. Their ideas aren't well-known outside the field and even amongst data visualisation practitioners, they are often neglected. I’d like to change that. I’m fascinated by the psychological aspect of data visualisation. If we are going to communicate our message effectively then we need to understand how our audience will perceive and comprehend the information that we present to them. Data visualisation is the front line between data and decision making We should be aiming to make the transition of information from page/screen into our readers’ brains as seamless as possible. To do this well, we all need to know the science and psychology behind effective data visualisation. Some examples:
Tools like Excel, Tableau, Qlik, Cognos or Power BI and languages like D3, R or WebGL will allow you to create a vast array of different visualisations but they will never be able to tell you how to most effectively communicate your message. Data visualisation tools and languages are constantly evolving and it is obviously important to know your tools and to be aware of technical developments within the field. However, this will always be secondary to knowing the value of, and methods behind, effective communication and so I’d encourage everyone to find out as much as they can about the theory behind their craft. If you’d like to know more then please get in touch! I read a lot! I also keep a spreadsheet which lists and grades the 120+ books I’ve read since June 2015 and have written up detailed notes about my favourite reads. I’m well aware of how sad this makes me. I’ve read many of the leading texts about data visualisation; Stephen Few, Edward Tufte and Alberto Cairo are my top 3 inspirations here. However, what I enjoy most is reading about people and trying to understand why we behave the way that we do. To this end, I read a lot about psychology and related fields. To give you an idea of what I’ve read, take a look at the top of this page to see the“recently read” section of my bookcase. If I were to select one book that I think everyone should read it would be Thinking Fast & Slow by Daniel Kahneman. This book has taught me so much about human behaviour and why people are not as rational as they like to think they are. The insight I’ve gained from this book is hugely relevant to a vast range of subjects and practices. One of my main goals is to spread Daniel Kahneman’s word amongst Analysts, Accountants, Researchers, and anyone else working with data visualisation.  After Daniel Kahneman, I’d recommend pretty much anything by Steven Pinker.
As a final thought, I also like to read fiction when I can find the time. My all-time favourite novel is probably Jonathan Franzen’s Freedom. I’d find it hard to explain why I love this book so much but it contained such brilliant, relatable, yet tragic personalities. I found it to be as effective an exploration of human behaviour as any work of nonfiction. Other writers I love include John Irving, Mark Haddon, Matt Haig and Hanya Yanigihara. I’m always looking for inspiration on what to read next so please get in touch if you have any ideas for me. |
ABOUT MEAll content & opinions are those of the author 
Archives
July 2020
Categories |

 RSS Feed
RSS Feed
|
|
|